◎ Programmers
오랜만에 프로그래머스 문제를 풀어보았다. Lv 0인데도 불구하고 가끔씩 정말 어려운 문제가 껴있는 것 같다. 분주하게 레벨을 올려 나가야 할 것 같다.
문제를 풀면 풀수록 파이썬은 코테를 위한 언어라는 것이 실감된다. 코테는 누가, 얼마나 더 많은 함수를 알고 있고 잘 사용할 수 있는가의 싸움인 것 같다.
---
1) items()
items() 함수는 딕셔너리에서 키와 값을 동시에 추출할 수 있는 함수이다. 단순한 내용이니 아래 예시를 한번 확인해보자.
dict_a = {
'a': 1,
'b': 2,
'c': 3
}
# 1. 딕셔너리 전체 값 출력
print("case 1)")
print(dict_a.items())
print()
# 2. for 반복문과 함께 사용
print("case 2")
for key, value in dict_a.items():
print(f"key: {key}, value: {value}")
print()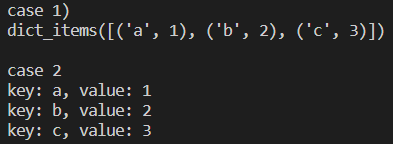
2) count()
count() 함수는 리스트 내의 각 항목의 개수를 반환하는 함수이다. 리스트 뿐만 아니라 iterable 형태의 자료형(dictionary, set은 불가능)이면 모두 가능하다. 이 함수는 보통 '리스트 내의 중복된 항목이 있을 때 각 항목의 개수가 필요한 상황'에 사용된다. 기본 형태는 다음과 같다.
(iterable).count(찾고자 하는 값)이를 사용하여 list, tuple, 문자열 자료형 내의 각 항목의 개수를 확인해보는 코드를 아래에 보였다.
list_a = ['a', 'a', 'b', 'c', 'c', 'c']
tuple_a = ('a', 'b', 'b', 'b', 'c', 'c')
str_a = "abAABBabab"
# 1. list 자료형
print("case 1. list")
print(list_a)
print(f"a: {list_a.count('a')}")
print(f"b: {list_a.count('b')}")
print(f"c: {list_a.count('c')}")
print()
# 2. tuple 자료형
print("case 2. dict")
print(tuple_a)
print(f"a: {tuple_a.count('a')}")
print(f"b: {tuple_a.count('b')}")
print(f"c: {tuple_a.count('c')}")
print()
# 3. 문자열 자료형
print("case 3. 문자열")
print(str_a)
print(f"ab: {str_a.count('ab')}")
print(f"A: {str_a.count('A')}")
print(f"AB: {str_a.count('AB')}")
이를 활용하는 방법의 한 가지로는 특정 원소를 가지는 리스트가 있을 때, 전체 원소의 수가 같고 동일한 인덱스에 각 항목의 수를 갖는 새로운 리스트를 생성하는 것이 있다. 말로만 하는 것보단 아래 코드를 확인해보자.
list_a = [1, 1, 2, 3, 3, 3, 3]
list_b = [list_a.count(i) for i in list_a]
print("list_a:", list_a)
print("list_b:", list_b)
3) index()
index() 함수는 리스트에서 값이 존재하는 첫 번째 인덱스 번호를 반환하는 함수이다. 첫 번째 인덱스라 함은 리스트 내의 동일한 항목이 여러 개 있을 때 가장 앞쪽에 있는 항목의 인덱스 번호를 반환한다는 것이다. 대표적인 형태는 다음과 같다.
# 전체 범위 탐색
(list).index(값)
# 시작 범위 지정
(list).index(값, 시작인덱스)
# 시작, 끝 범위 지정
(list).index(값, 시작인덱스, 끝인덱스)만약 시작 인덱스와 끝 인덱스를 지정했는데 이 사이에 찾고자 하는 값이 없을 경우 ValueError 예외가 발생하게 된다. 위 3개의 index() 함수 사용 예시를 아래 코드에 보였다.
list_a = ['a', 'b', 'c', 'a', 'b', 'c', 'd']
# case 1. 전체 범위 탐색
print("case 1. 전체 범위 탐색")
print(f"'a' 인덱스: {list_a.index('a')}")
print(f"'b' 인덱스: {list_a.index('b')}")
print(f"'c' 인덱스: {list_a.index('c')}")
print(f"'d' 인덱스: {list_a.index('d')}")
print()
# case 2. 시작 범위 지정
print("case 2. 시작 범위 지정")
print(f"'a' 인덱스: {list_a.index('a', 3)}")
print(f"'b' 인덱스: {list_a.index('b', 3)}")
print(f"'c' 인덱스: {list_a.index('c', 3)}")
print(f"'d' 인덱스: {list_a.index('d', 3)}")
print()
# case 3. 시작, 끝 범위 지정
print("case 3. 시작, 끝 범위 지정")
print(f"'a' 인덱스: {list_a.index('a', 1, 4)}")
print(f"'b' 인덱스: {list_a.index('b', 2, 5)}")
print(f"'c' 인덱스: {list_a.index('c', 3, 6)}")
print(f"'d' 인덱스: {list_a.index('d', 1, 5)}") # 예외 발생
print()