◎ 프로그래머스(Programmers)
코드업 파이썬 기본 문제인 6000번대를 모두 끝내고 프로그래머스로 넘어온 첫날이다. 난이도가 낮은 Lv.0 문제를 풀어보고 다른 사람의 풀이도 확인하였는데 간단한 문제라도 러닝 타임의 차이가 많이 날 수 있다는 것을 확인할 수 있었다. 파이썬에는 문제를 푸는 데에 있어 유용한 함수들이 정말 많이 존재하는 것 같다.
1) swapcase()
swapcase() 함수는 영어 문자열의 대소문자를 변경해주는 함수이다. 입력한 문자열의 소문자는 대문자로, 대문자는 소문자로 출력하는 문제에서 접하게 되었다. 이 함수를 사용하지 않았던 내 코드는 다음과 같다.
str = input()
for i in range(len(str)):
if str[i].islower():
print(str[i].upper(), end='')
else:
print(str[i].lower(), end='')문자열을 입력받고 문자 하나씩 소문자 여부를 확인하여 변경하는 내용이다. 복잡하지 않은 내용이지만 swapcase() 함수를 사용하면 이보다 더 간결하게 나타낼 수 있다.
print(input().swapcase())정말 맥이 탁 빠질 정도로 간결해진 모습이다. 파이썬을 사용한 코딩테스트는 함수를 얼마나 많이 알고있고 사용할 줄 아는지의 싸움인 것 같다.
2) print(f"...")
여기서 f란 formatted를 뜻하는 것으로, 문자열 자료형이 가지고 있는 format() 함수의 사용을 보다 편리하게 해준다. 기존의 format() 함수를 사용한 방법과 f를 사용한 방법을 비교해보자.
a, b = input().split()
# 1. format() 함수 사용
print("a is {0}, b is {1}".format(a, b))
# 2. print(f"...") 사용
print(f"a is {a}, b is {b}")format() 함수를 사용할 때와는 달리 중괄호 안에 들어가야 할 변수가 바로바로 들어가므로 보다 직관성있게 코드의 내용을 파악할 수 있는 장점이 있는 것 같다. 실제 코딩테스트를 보면 format() 함수보단 f를 붙여 사용하는 경우가 많은 것 같다.
3) print(r"...")
여기서 r이란 raw를 뜻하는 것으로, 문자열을 raw 형태로 즉, 가공되지 않은 본 형태 그대로 출력해준다. 여기서 가공은 이스케이프 문자(\)를 뜻하는데 r을 붙이게 되면 파이썬은 해당 문자열 내의 이스케이프 문자를 2개로 인식한다. 무슨 말인지 아래 사진을 통해 확인해보자.

r을 붙이지 않은 문자열은 두 개의 이스케이프 문자를 그대로 출력하지만 r이 붙은 문자열은 각 이스케이프 문자를 2배 하여 출력하고 있다. 이를 print() 함수에 적용하면 다음과 같다.

이처럼 r을 사용하면 이스케이프 문자가 포함된 문자열을 본 형태 그대로 출력할 수 있다. r이 붙은 형태인 Raw String은 regex를 사용하여 문자열을 찾는 경우, Pattern을 설정하는 경우에 자주 사용한다고 한다.
4) replace()
replace() 함수는 문자열 내의 특정 문자를 원하는 문자로 바꾸어 주는 함수이다. 문자열 내의 공백이나 특정 문자를 기준으로 분할을 하기 전에 사용되곤 한다.
string = "Hello Python!"
print(string.replace("!", "^_^"))
replace() 함수의 세번째 매개변수를 통해 대체할 문자의 개수를 지정할 수도 있다. 아무것도 주지 않으면 모든 문자를 대체하는 것이 기본값이다.
string = "Hello Python!!!"
print(string.replace("!", "^_^", 1))
이를 응용하면 수식 내의 숫자를 분리하여 저장할 수 있다. 아래와 같이 활용되곤 한다.
string = "10*20-100+50"
print("원본:", string)
string = string.replace("*", " ").replace("-", " ").replace("+", " ")
print("변경:", string)
string = string.split()
print("split():", string)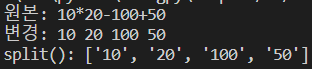
5) '::'
문자열이나 리스트 등의 시퀀스 객체는 슬라이싱(slicing)을 통한 탐색이 가능하다. 슬라이싱이 설정한 범위 만큼 탐색하는 것인데 마지막 범위는 제외된다는 특징이 있다. 아래는 슬라이싱의 기본적인 예이다.
string = "HELLO"
print(string[2:4])
temp_list = [0, 1, 2, 3, 4]
print(temp_list[:3])
슬라이싱을 통해 탐색을 할 때 기준 인덱스로부터 탐색할 간격을 설정할 수 있다. 콜론을 하나 더 사용하고 그 뒤에 간격을 입력하면 된다.
string = "HELLO"
print(string[1:4:2])
temp_list = [0, 1, 2, 3, 4]
print(temp_list[::3])
이를 활용하면 문자열의 출력을 반대로 하는 것을 손쉽게 할 수 있다.
string = "Hello Python !"
print(string[::-1])
6) zip()
zip() 함수는 개수가 동일한 2개 이상의 iterable 자료형이 존재할 때 동일한 순서(인덱스)의 요소를 튜플(tuple) 형태로 묶어 iterator 형태로 새롭게 만드는 함수이다. 여기서 iterator이란 상태를 유지하며 순회 가능한 객체를 뜻하는데 자세한 내용은 아래 글에 정리해두었다.
[Python] :: 이터러블(Iterable) 및 이터레이터(Iterator)와 제너레이터(Generator)
◎ 이터러블(Iterable) 및 이터레이터(Iterator) 1) 이터러블(Iterable) 이터러블이란 순회 가능한 모든 객체, 즉 list, tuple, set, dict, range, str, 문자열, 파일 등을 말한다. 쉽게 생각해서 for 문의 in 키워드
semin1127.tistory.com
아래는 zip() 함수의 기본적인 사용 예이다.
str1 = "aaaaa"
str2 = "bbbbb"
str3 = "ccccc"
print(zip(str1, str2))
print(list(zip(str1, str2)))
print(zip(str1, str2, str3))
print(list(zip(str1, str2, str3)))